LiveID chemometric modelling software
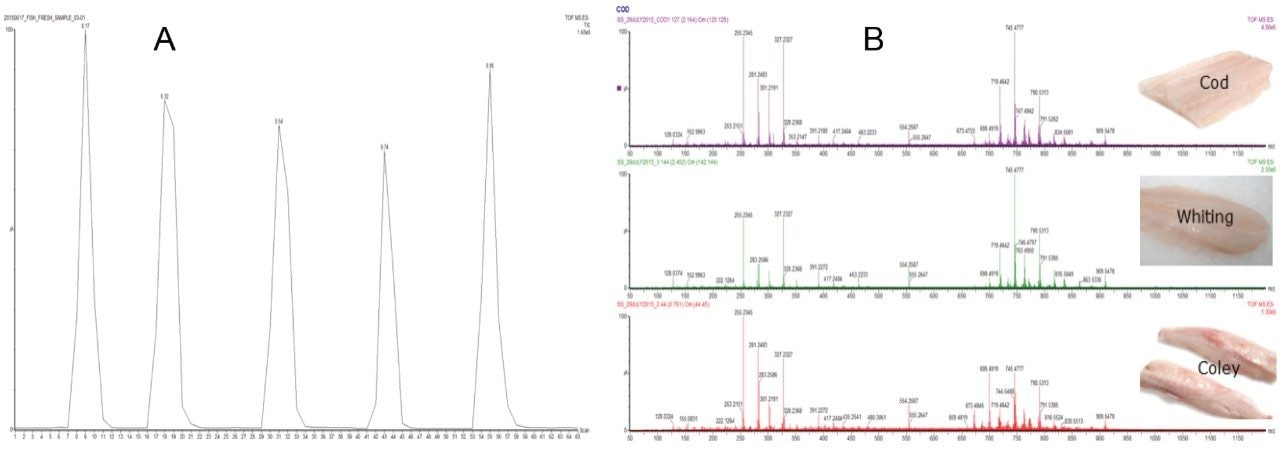
Multivariate statistical software package LiveID (v.1.1) was used as a model builder and recognition tool. To generate models from the untargeted profiling REIMS ToF MS data acquired in MassLynx MS Software (v.4.1) the following data pre-treatment steps were performed: lock mass correction applied using the Leu Enk ion at m/z 554.2615; all spectra contained within each “burn event” termed the region of interest (ROI) were combined to form a single continuum spectrum; Adaptive Background Subtraction (ABS) algorithm was applied to reduce the chemical background in the combined spectra; data resampling (binning to 0.5 Da) was performed to reduce the data dimensionality; the resulting spectrum was normalized using the Total Ion Chromatogram (TIC). All chemometric models were calculated using the mass region of 600–950 m/z. The peak detection threshold was automatically set within LiveID from file to file based on the minimum spectral intensity value plus 10% of the difference between the maximum and minimum intensities.
T = IntensityMin + 0.1*(Intensity Max – Intensity Min)
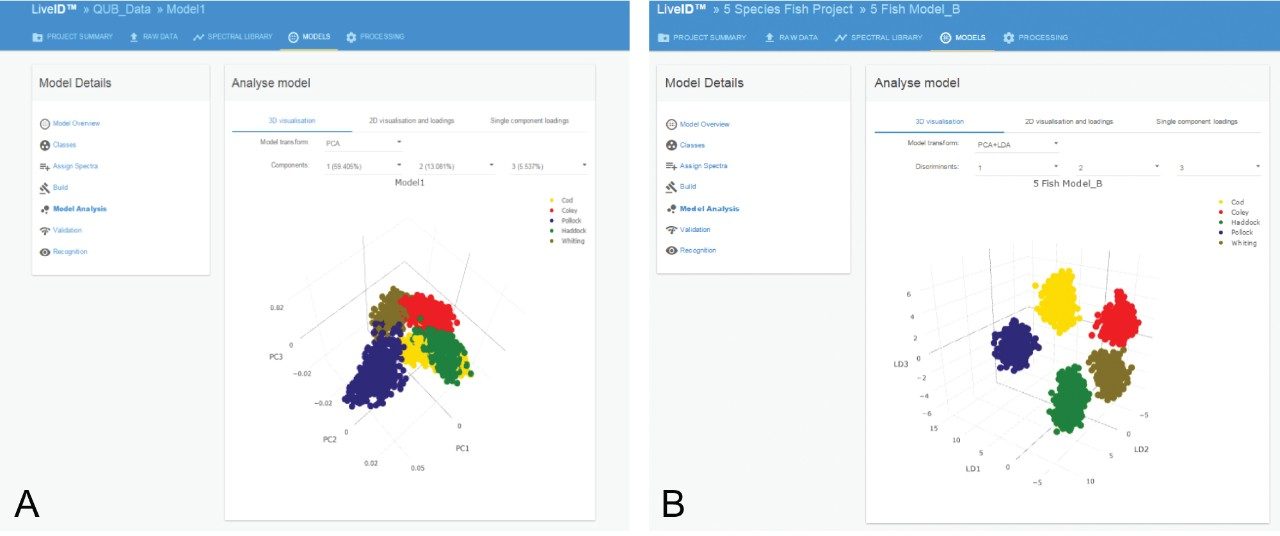
Following data pre-treatment steps, a Principal Component Analysis (PCA)/Linear Discriminate Analysis (LDA) model was generated. First, an unsupervised PCA (Singular Value Decomposition algorithm) transform was applied to the spectral data calculating the scores and loadings plots; a supervised LDA transform was then applied to the scores calculated by the PCA transform. LDA is a transform that maximizes the inter-class variance, while minimizing the intra-class variance, resulting in a projection where examples from the same class are projected close to each other and, at the same time, the class centers (means) are as far apart as possible. Although it is not a true regularization technique, PCA-LDA is found to reduce the chance of over-fitting that may occur with a pure LDA model.
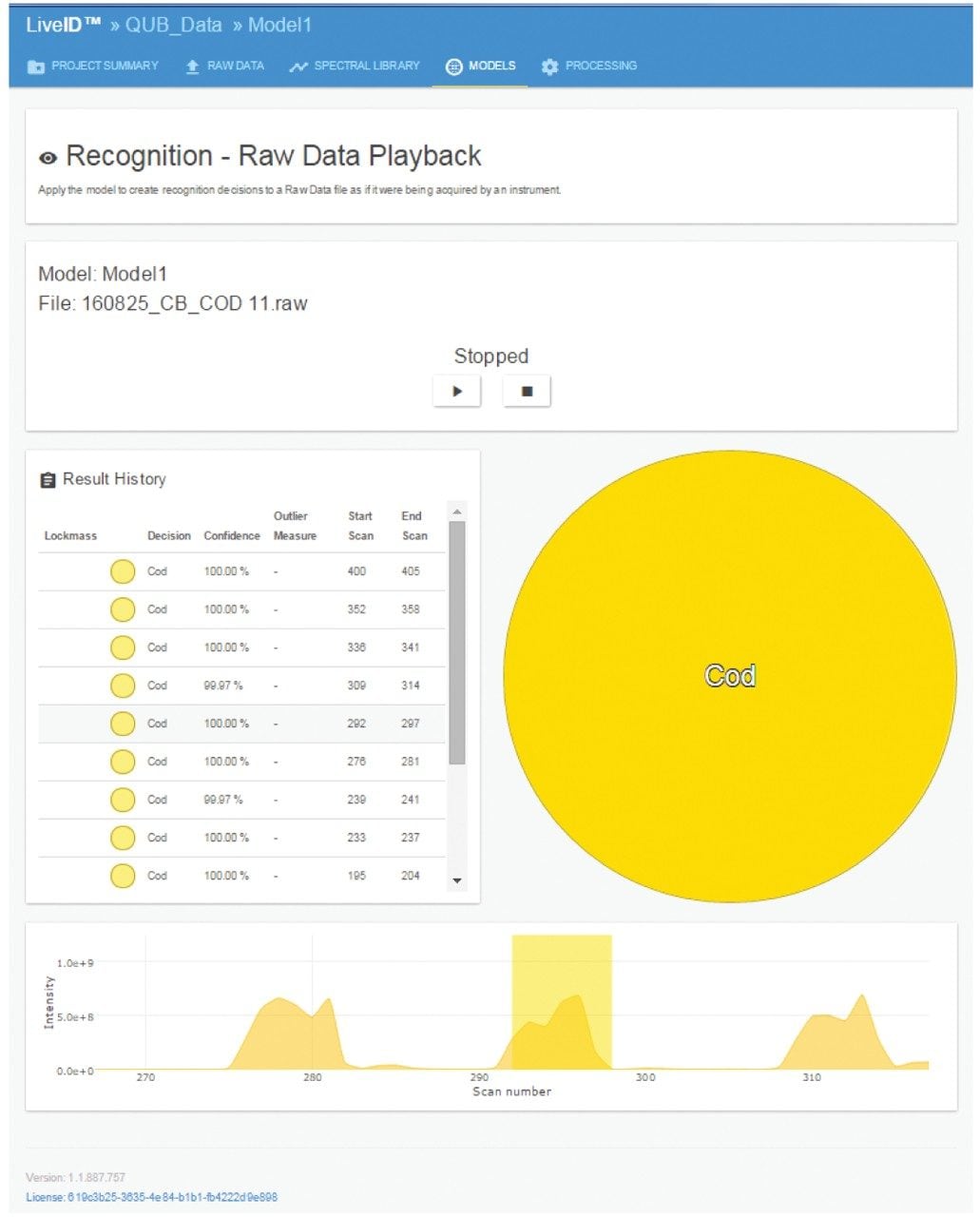
During the recognition step, the model transformed spectra acquired from test samples with an unknown classification into the associated model-space, after which, a classifier determined into which class (if any) the spectra belonged. The model classifier uses a multivariate normal distribution (MVN) for each model class. During the model building phase, these distributions are constructed by transforming the training spectra to generate scores for the n principal components/ linear discriminants selected for the model. The number of dimensions in the MVNs is also equal to n. The MVNs produced a likelihood measure for each class, and Bayes' rule was then applied to derive posterior probabilities.
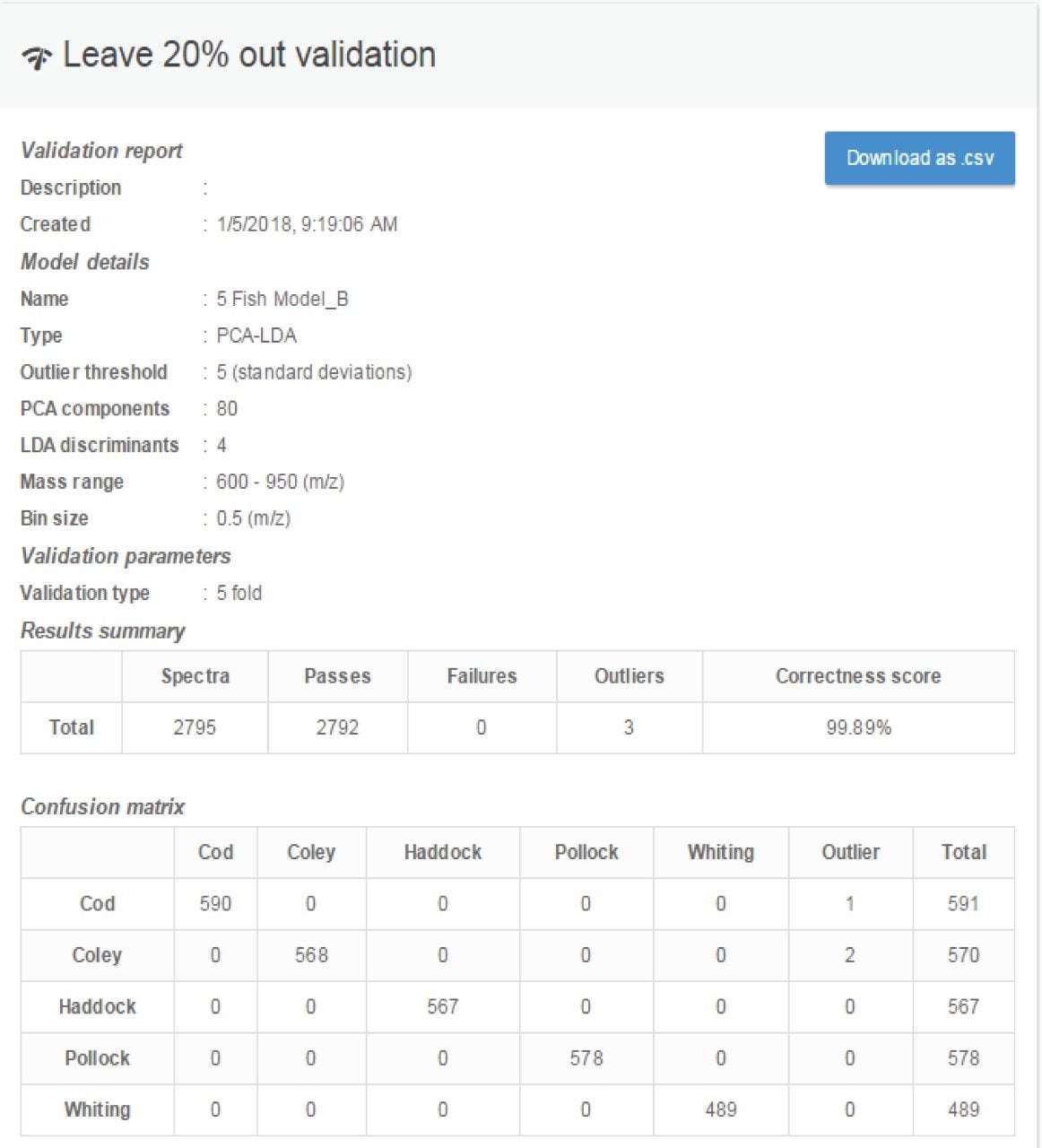
In silico 5-fold stratified validation was performed to determine the predictive accuracy of the fish speciation model. The model building dataset was divided in five partitions (5-fold), each of which contains a representative proportion of each class within it (stratified). Four partitions (80%) of the dataset were used to build a model under the same conditions as the original model. This model was used to predict the classifications of the one partition (20%) of the training set that was left out. The cycle was repeated iteratively five times and each partition was predicted once by a model trained from the other four. The output of the validation details the total number of correct and incorrect classifications, as well as the number of outliers. Outliers were calculated according to the Mahalanobis distance8 to the nearest class center. If this distance was greater than the outlier threshold, the sample was considered an outlier.
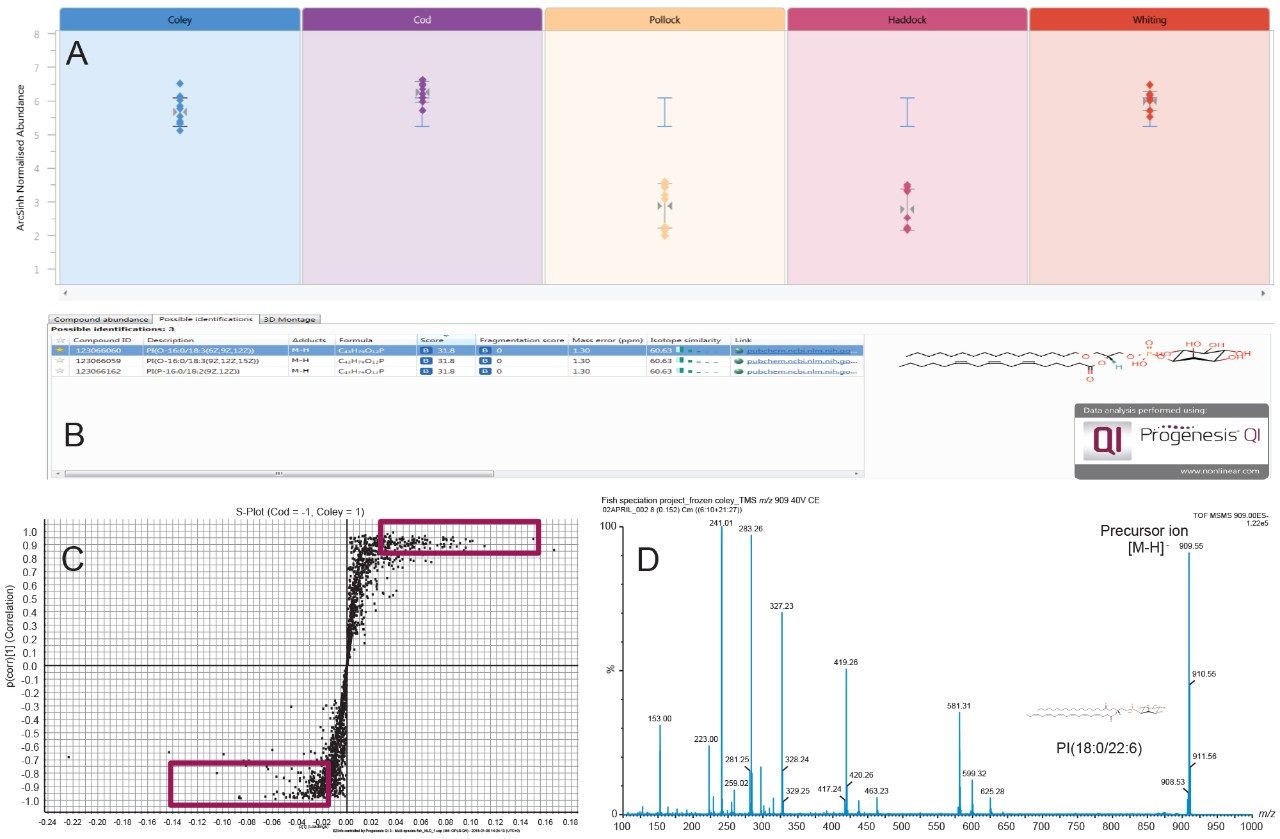
Additional and complementary statistical analyses were performed using Progenesis QI (NonLinear Dynamics, Newcastle, UK), EZInfo, and SIMCA-P (Umetrics Sartorius Stedim Biotech, Sweden) to determine the chemical identifications of candidate biomarkers and potential involvement of discrete biochemical pathways.