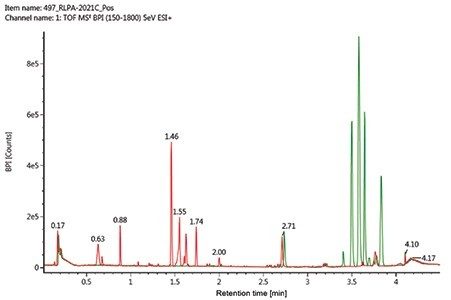
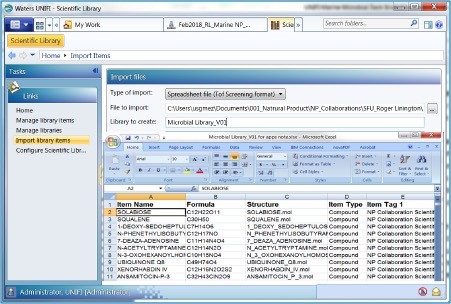
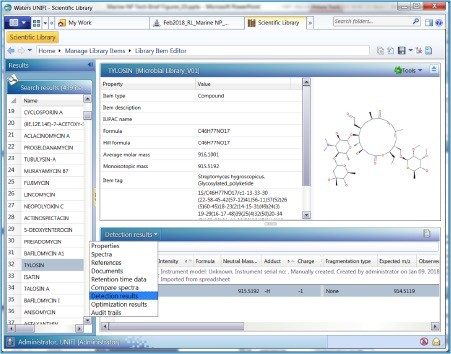
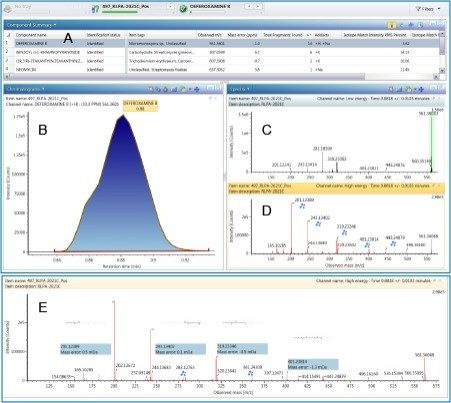
In any non-targeted discovery experiment, the goal is to identify as many compounds as possible. However, compound identification has always been a challenging step due to sample complexity and the absence of relevant microbial databases. In order to address this issue, a natural product analytical workflow was used to analyze the mass spectra of marine extracts using a custom microbial natural product database with precursor exact mass, fragment ion information, and theoretical isotopic distribution that allows confident identification of compounds from a complex sample. As shown in Figure 2, it is simple and straight forward to create a compound database in the UNIFI Scientific Library. In order to create a UNIFI Scientific Library, .mol files are required for each of the compounds of interest and an Excel spreadsheet containing the name of the compound of interest, molecular formula, the name of the corresponding .mol file and item tag (such as compound class and Latin name) were created in the same folder. Other measured parameters such as fragment ion, retention time, and collision cross section can also be added to the library. Then, the spreadsheet was imported into UNIFI as a scientific library container (.ULC) to create the microbial database with a total of 439 compounds. Detailed step-by-step explanation on how to create a scientific library using UNIFI is provided elsewhere.3 The basic infrastructure of the UNIFI microbial database is shown in Figure 3 with compound name, chemical formula, structure, average molecular mass, monoisotopic mass, and item tag of each selected compounds. Figure 4 shows the compound identification result from the UNIFI microbial database. A data-independent acquisition (DIA) was used in order to acquire both precursor exact ion in low energy and corresponding fragment ion spectra in high energy from one injection. Figure 4, Panel A, shows the component table that lists all components that are identified from the UNIFI microbial library. For each identified compound, the extracted ion chromatogram (Figure 4, Panel B), low energy parent ion spectra (Figure 4, Panel C), and corresponding high energy spectra (Figure 4, Panel D) producing likely structural fragment ion matches are displayed. UNIFI compares and matches predicted in silico fragments with high energy experimentally derived fragments.