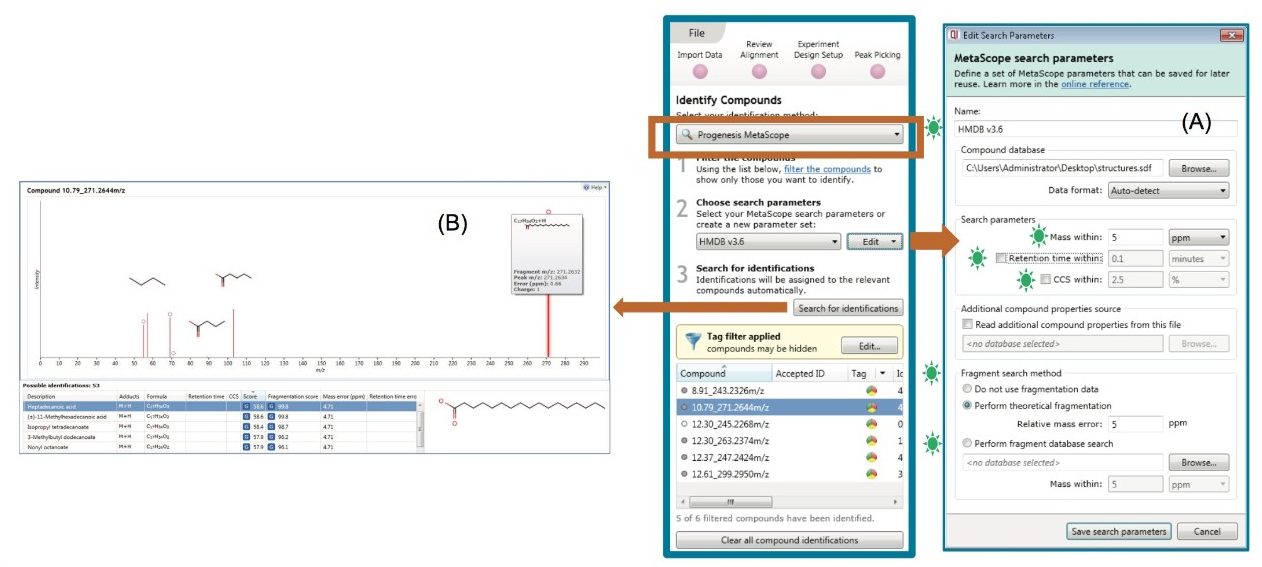
Data processing was performed using Progenesis QI, the latest OMICS software package from Waters fully able to utilize the information afforded in HDMSE datasets. Progenesis QI is a novel software platform that is able to perform alignment, peak picking and mining of data to quantify then identify significant molecular differences between groups of samples.
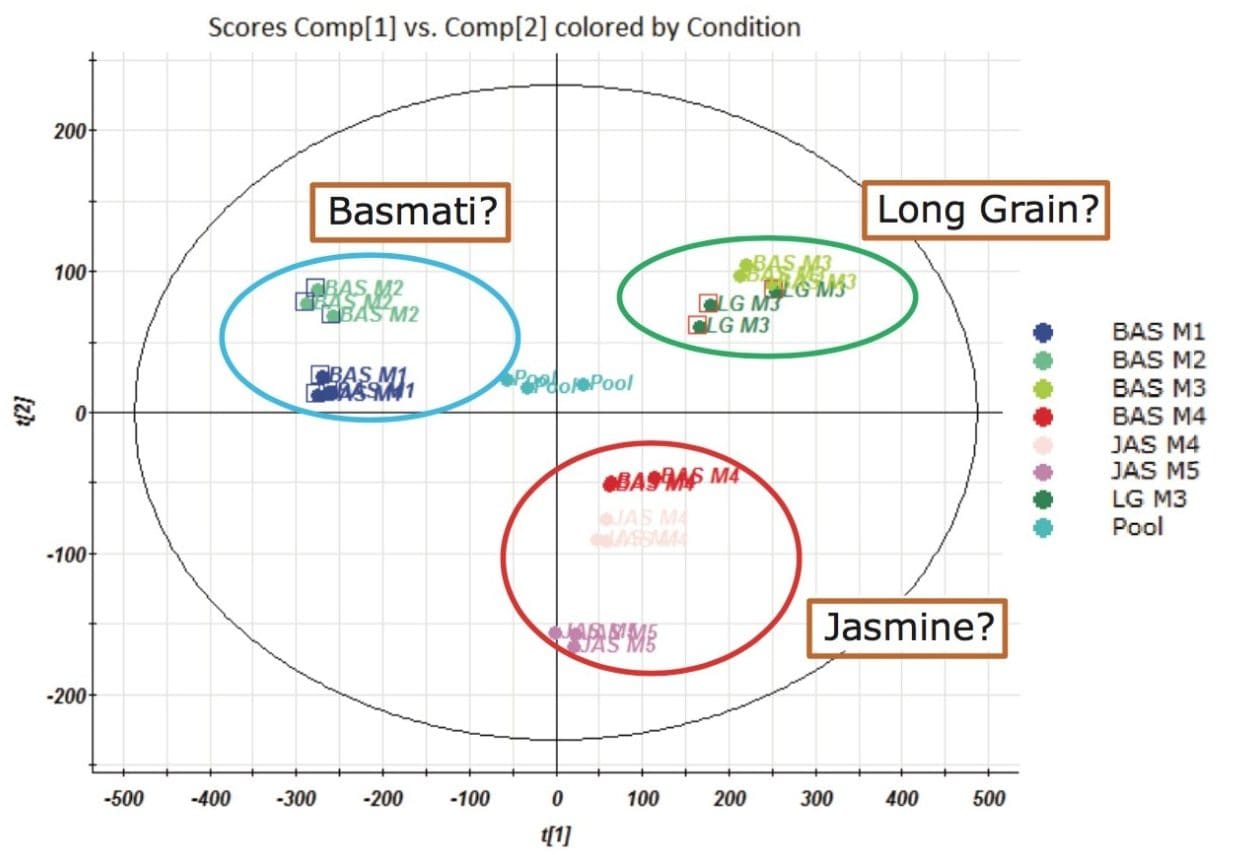
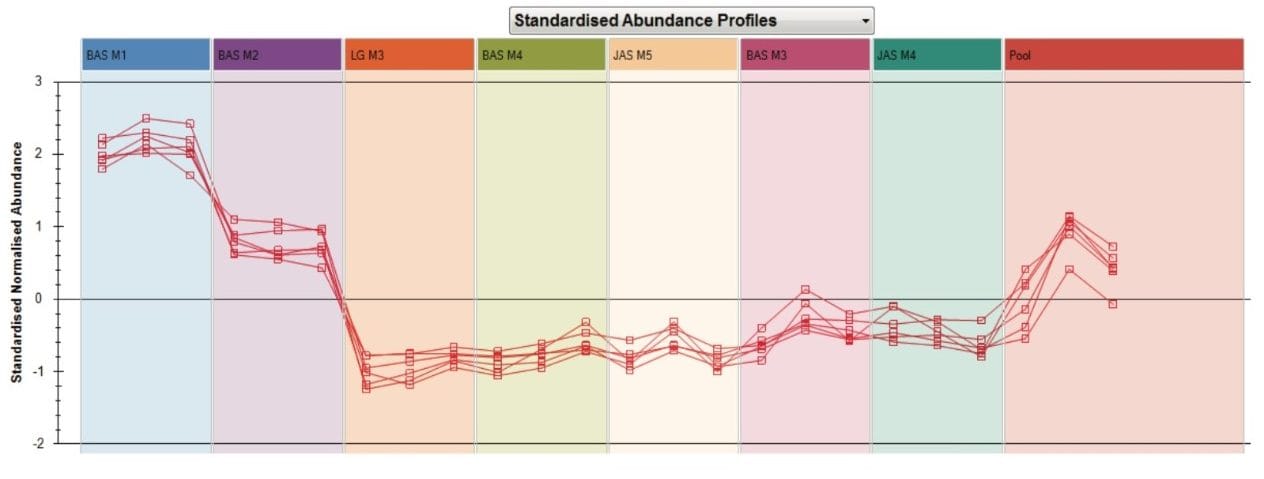
Following alignment, peak detection and deconvolution, 3885 compound ions were investigated. Initially, Principle Component Analysis (PCA) was performed yielding the scores plot in Figure 2. Tight pooling of injections from replicate samples and a centralized composite/pool sample indicated a statistically relevant dataset. Some of the basmati rice samples fell in the upper left quadrant, jasmine rice samples fell in the lower right quadrant and a long grain rice in the upper right quadrant. Exceptions to the pooling of the rice types were observed for two basmati rice samples. One originated from the same producer as a jasmine rice and pooled with other jasmine rice samples (BAS M4). The second basmati outlier (BAS M3) came from the same producer as the long grain rice and pooled alongside this long grain rice sample (LGM3).
Since the origin of these stored purchased samples is essentially unknown, it is not possible to draw conclusions about the origin or purity of the samples. The aim of this work was to devise a proof-of-principle method for the investigation of basmati rice authenticity and potential food fraud. A study with a larger number of well characterized samples, including both authentic and non-authentic basmati rice samples, is required. Finding unique markers of interest in this new study may then make it possible for a pass/fail method to be established on a more routinely used instrument in a quality control laboratory, such as a single or tandem quadrupole.
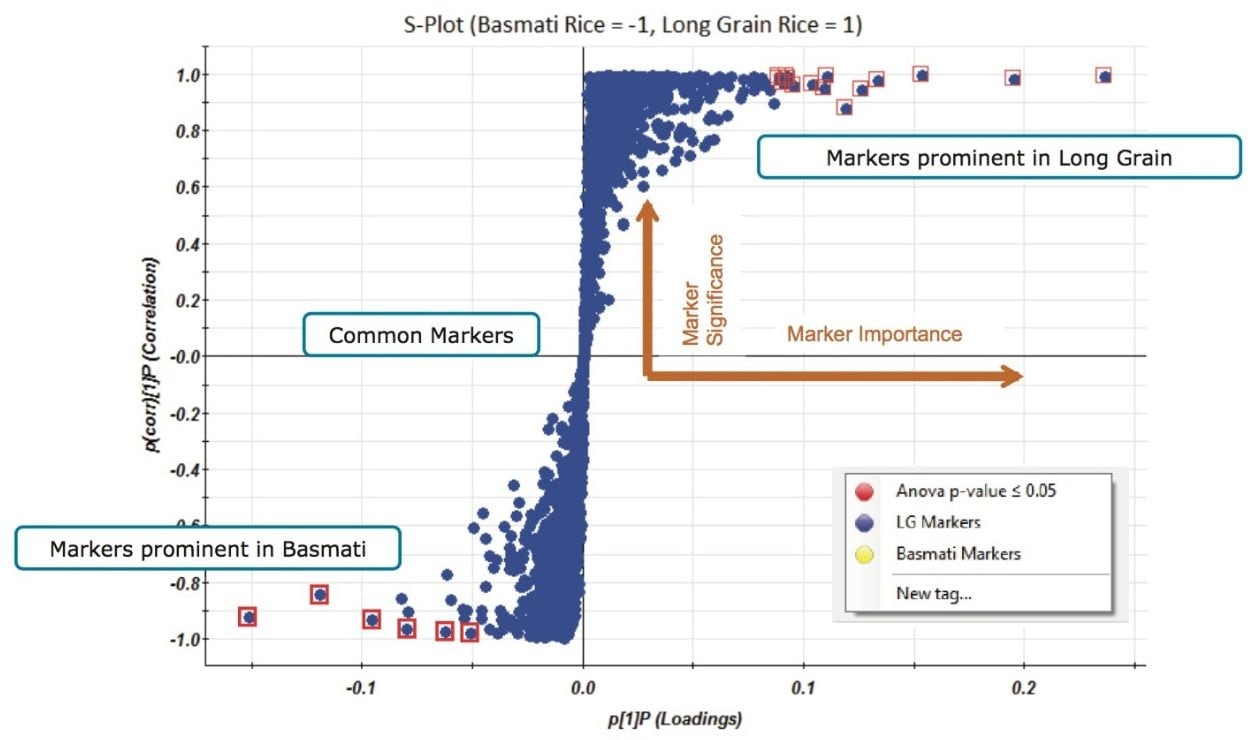
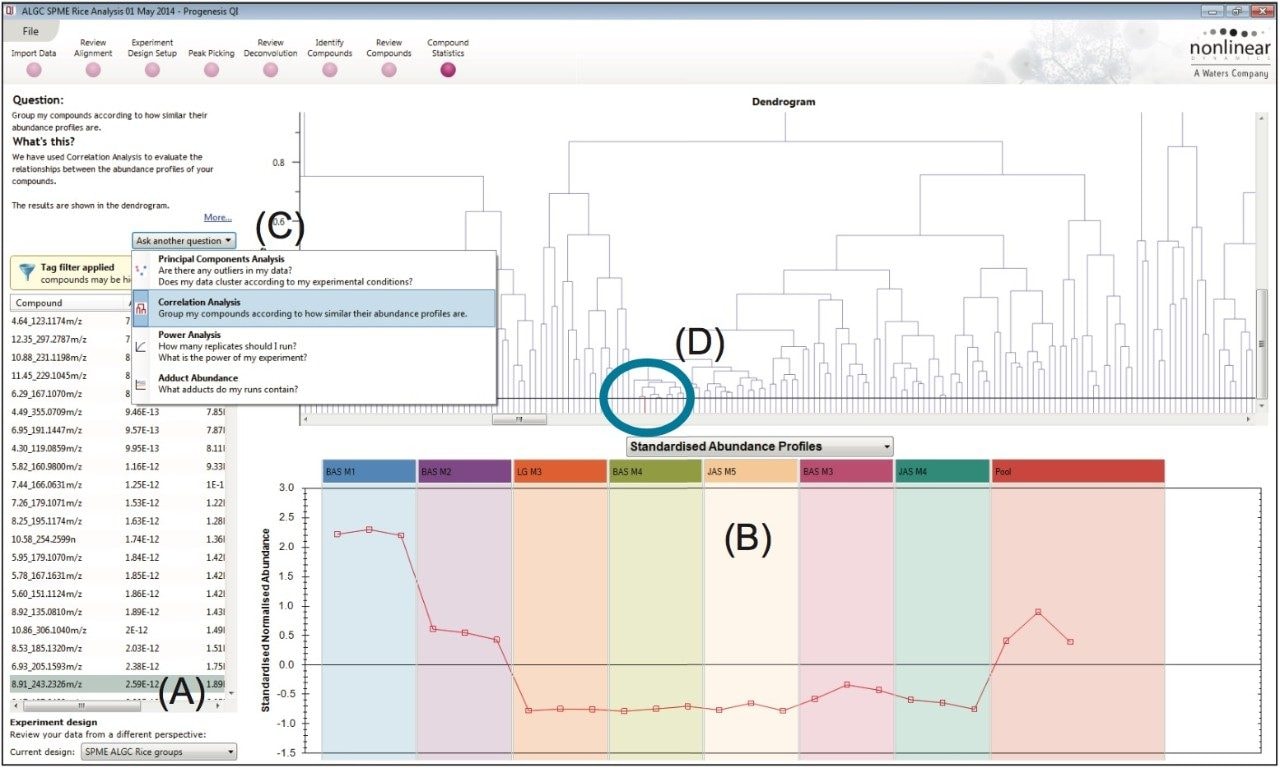
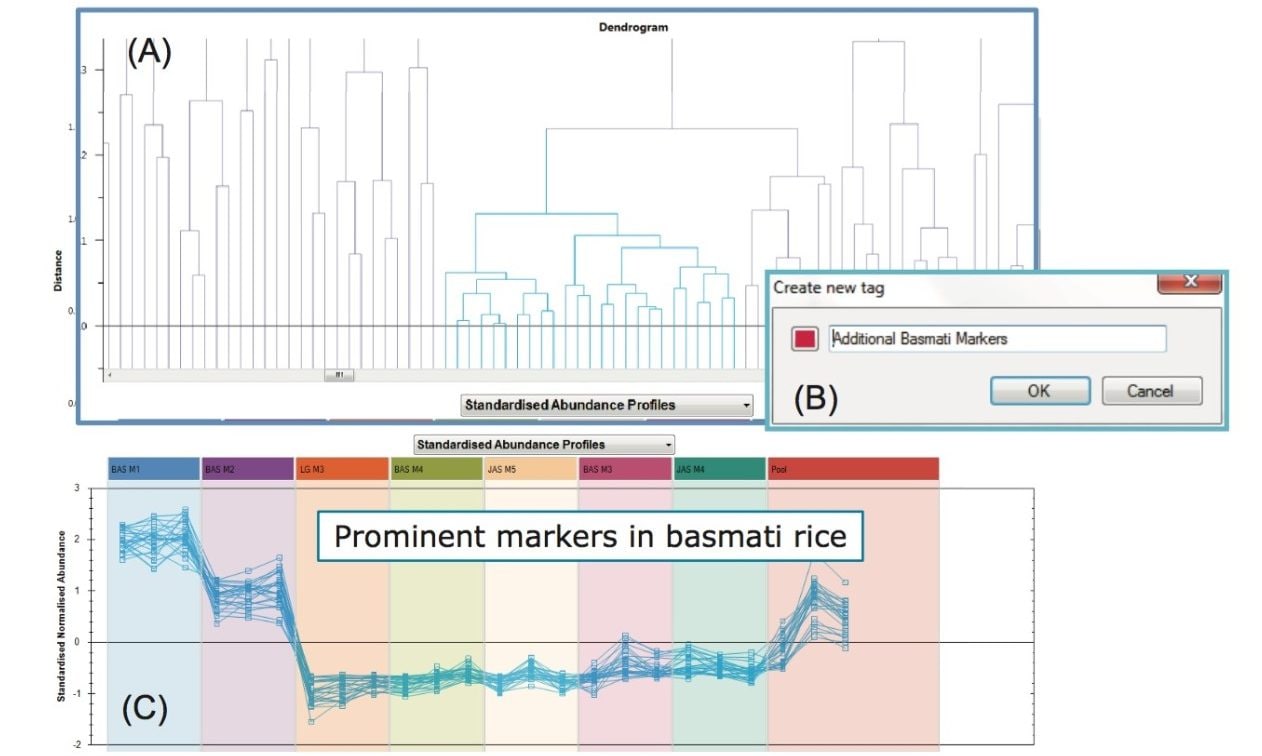
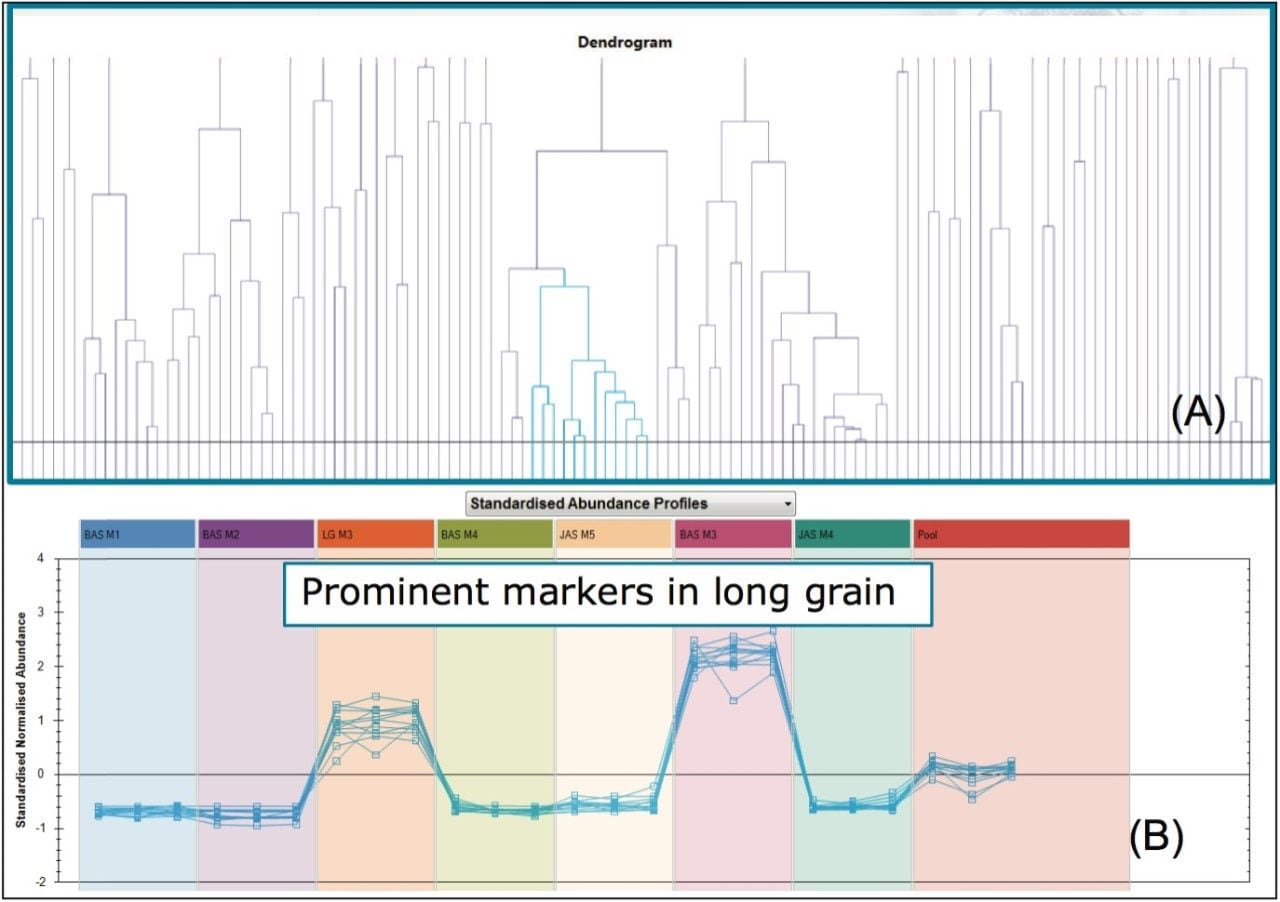
Further investigation into the data was performed using a supervised Orthogonal Projections to Latent Structures Discriminant Analysis (OPLS-DA) model. For this, the markers comprising the injections for the basmati rice samples (BAS M1 and BAS M2), highlighted with blue squares in Figure 2, were compared to the markers comprising the long grain rice sample (LG M3), highlighted with red squares in Figure 2. The S-plot from this analysis is shown in Figure 3 where the x-axis shows the measure of the magnitude of change in a particular analyte, and the y-axis shows a measure of analyte significance in the two-group comparison. Significant markers or ions of interest, highlighted with red squares in Figure 3, are the ions representing the significant markers with the biggest difference between the two rice types. Once highlighted, a set of markers can be tagged with a simple right mouse click. This subset of analytes can then be assigned a ‘tag’ within Progenesis QI for further consideration.