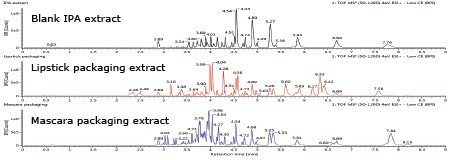
Discovery tool
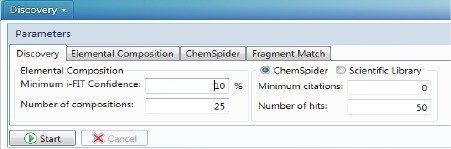
Regardless of whether a marker or candidate of interest was obtained by binary compare or multivariateanalysis, the next step in the workflow is structural elucidation. The Discovery tools within UNIFI’s Elucidation toolset include automated elemental composition, database searching through ChemSpider or UNIFI’s configurable Scientific Library, as well as fragment matching of high-collision energy data (Figure 6) of individual or batches of candidates. The best matches are displayed based upon the number of identified high energy fragments, citations from ChemSpider, and mass accuracy. The elemental composition algorithm uses accurate mass and isotope information to calculate the possible compositions for each marker. Using the Discovery tool settings, analysts can specify an acceptable level of isotope match (i-FIT), elements to be included in the elemental composition search, which libraries to select from ChemSpider (all or specific ones), and minimum number of citations in ChemSpider, among other things.
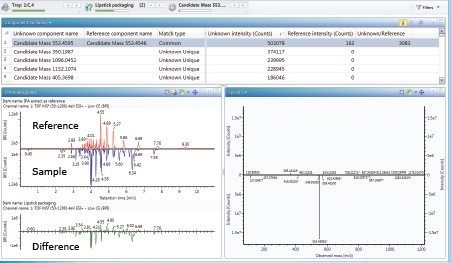
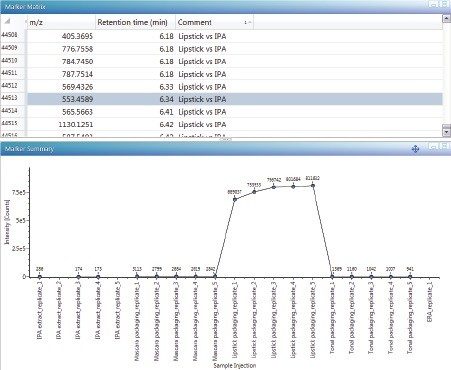
The final results for the candidate mass m/z 360.3236 in the mascara packaging are displayed in a table that lists the elemental compositions within specified limits, possible structures with citations from the ChemSpider database, and how many fragments can be matched to the high collision energy data for each structure (Figure 7).
Many polymer additives form adducts during LC-MS (Na+ being the most common). The adduct ion can be more intense than the protonated species, or the protonated ion can be absent entirely. In this case, the initial evaluation of the mass using +H ion, did not provide a reasonable molecular formula (no i-FIT above 50% and no structure from ChemSpider). Therefore Na+ was selected as an adduct and the Discovery tool process was repeated. As shown in Figure 7, the molecular formula C22H43NO has a 100% i-FIT, meaning that the isotope ratio for the m/z is consistent with the proposed composition. ChemSpider returned a lot of possible structural hits for this formula. When sorted by the number of citations, it can be seen that the top choice also has one of the highest
number of possible fragment matches in the high energy data. Additionally, common names are returned from the ChemSpider search that can help analysts determine the correct structure. Many polymer additives have common names such as Irganox’s or Tinuvin’s which are much easier to recognize than just a chemical name. The most cited chemical with the elemental composition C22H43NO has several common names indicating a polymer additive e.g. Armoslip E. Researching the identity of the chemical further, it turned out to be erucamide – a fatty acid derivative that is commonly used as a slip agent in packaging materials.