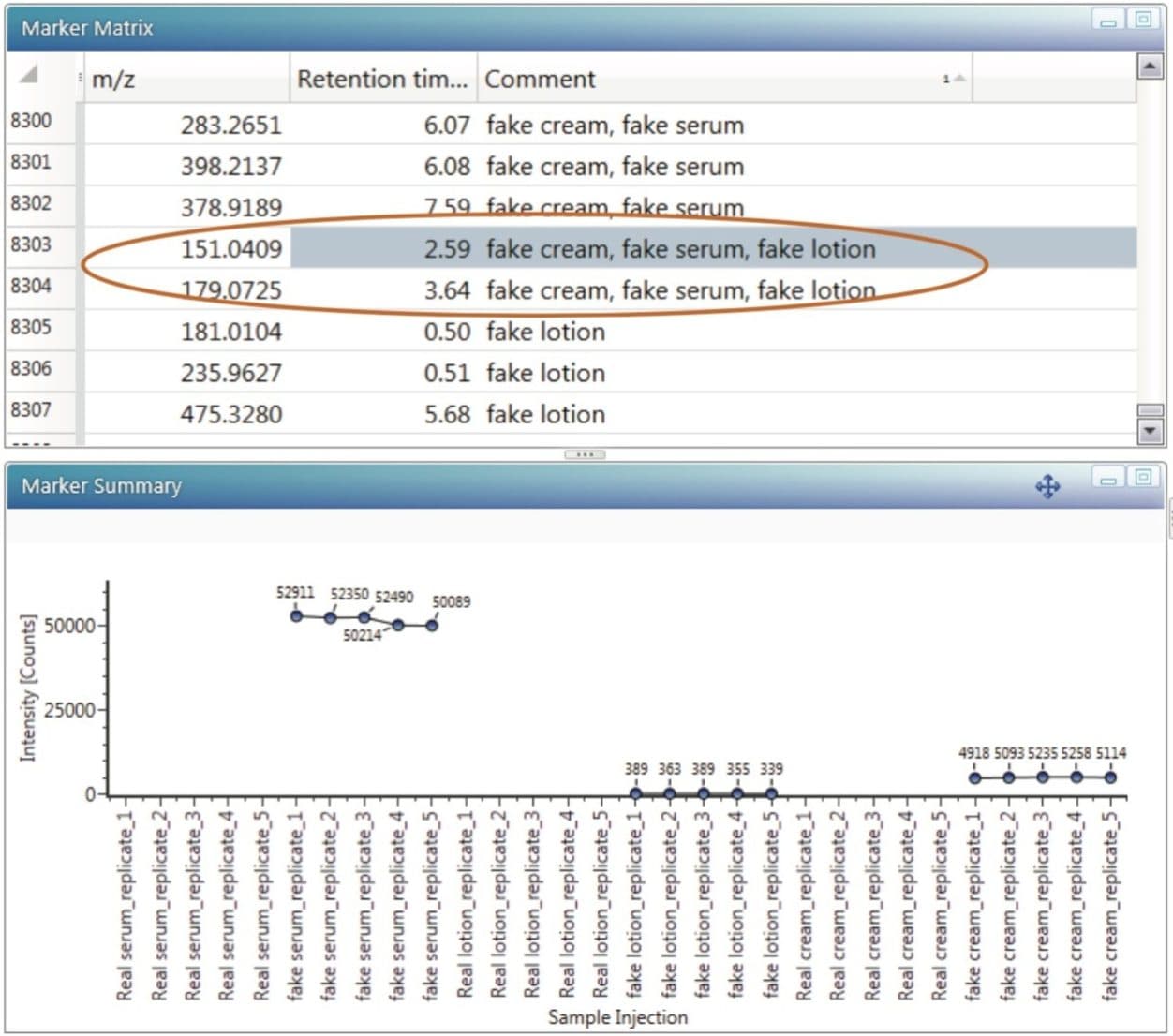
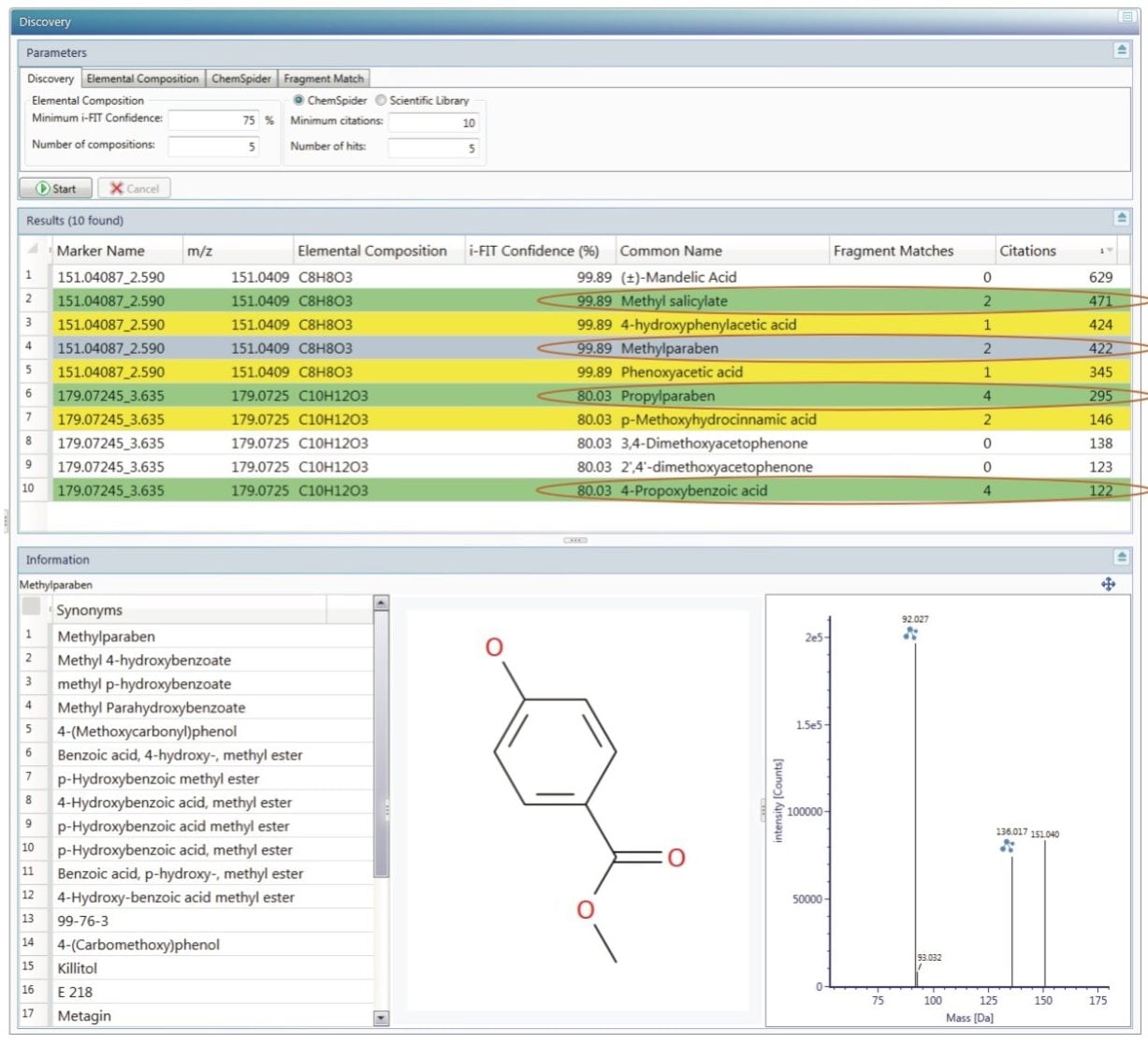
Samples were analyzed as five replicates in positive and negative ESI mode to obtain a representative data set in both ionization modes. Due to the lack of information about the counterfeit sample formulations, and for a more comprehensive analysis, data was acquired using different ionization modes as some compounds will ionize exclusively with positive ionization, and others only by negative ESI.
All sample data was processed using the multivariate analysis tools available in UNIFI Scientific Information System. UNIFI can generate marker matrices based upon user-defined criteria that can be automatically transferred to EZInfo software for MVA. The initial summary is presented as a PCA scores plot. In this initial plot no information about the individual sample groups is passed to the MVA software, and this model is said to be unsupervised.
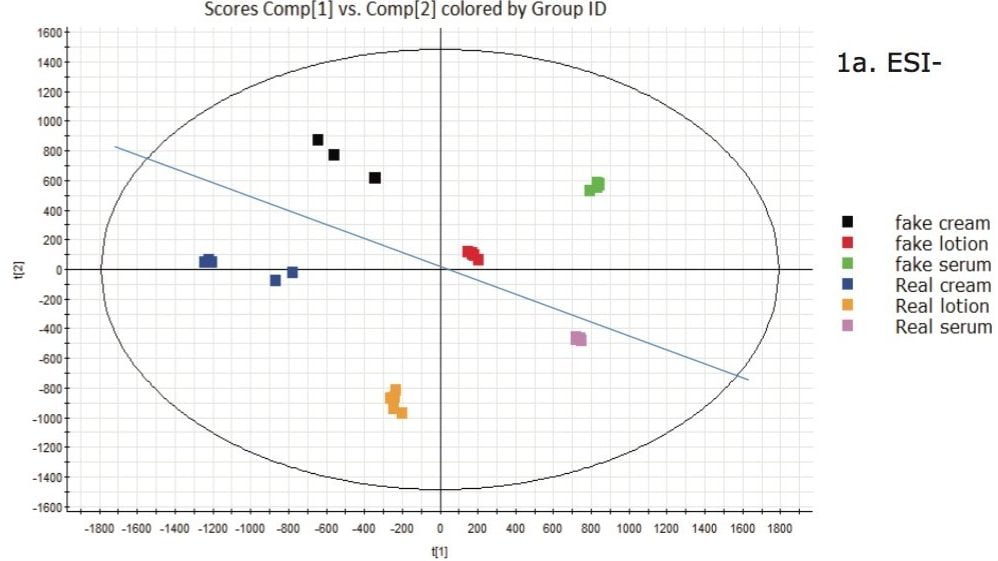
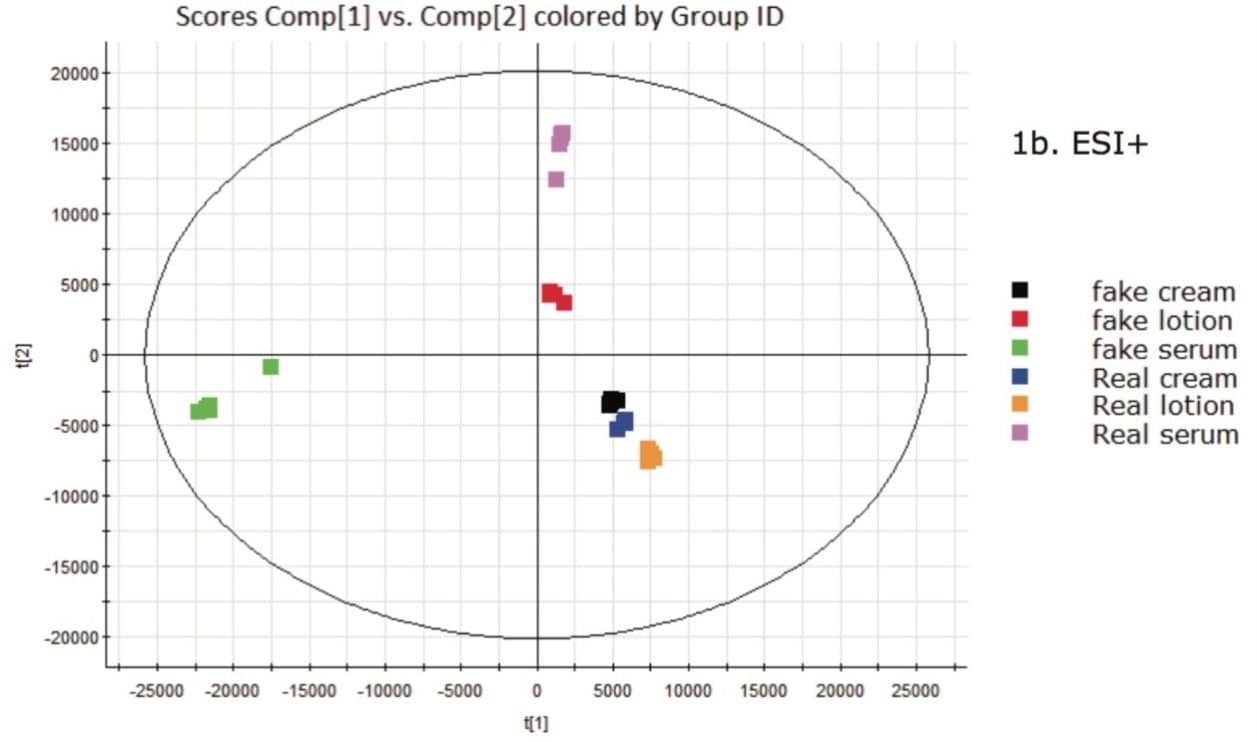
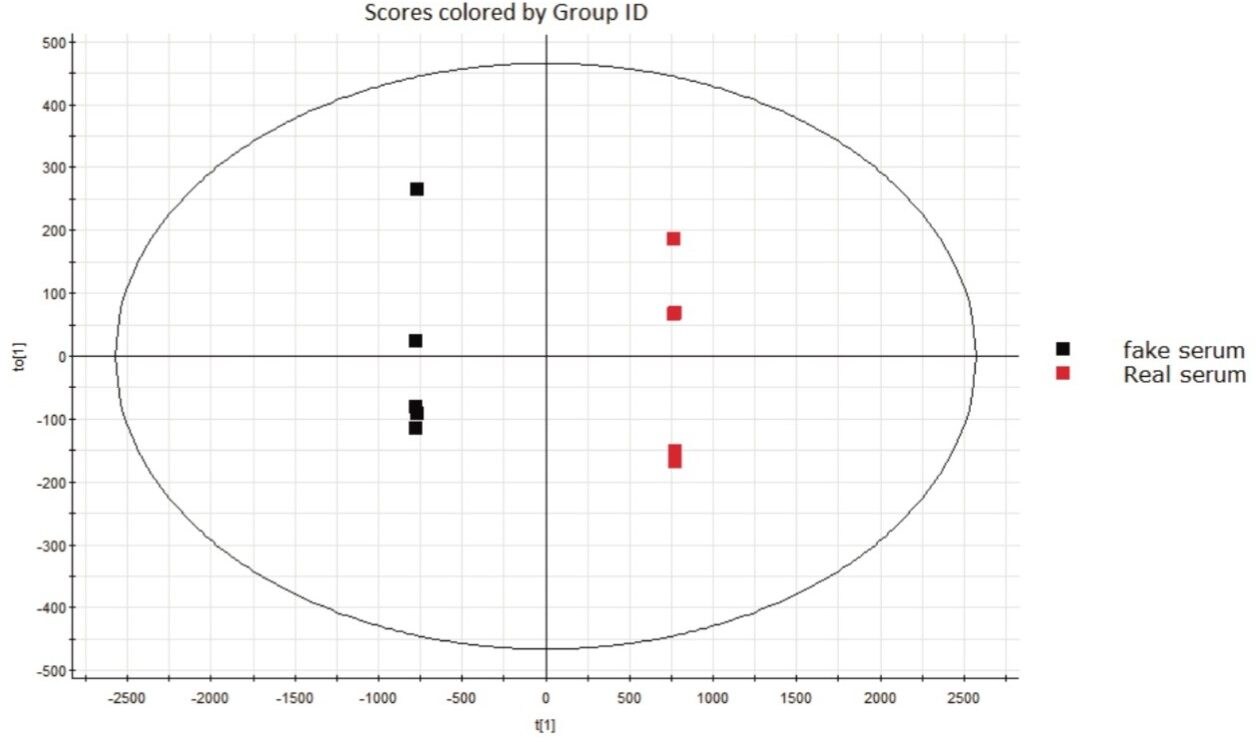
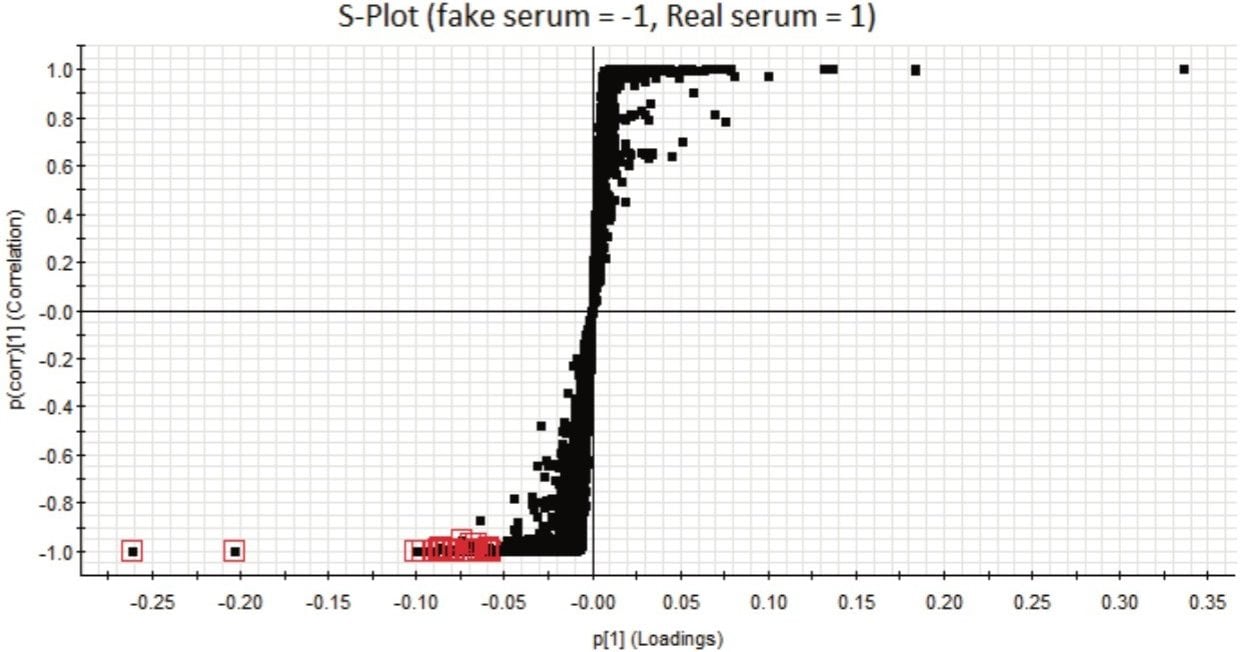
If additional discrimination among the investigated sample groups is required, a supervised analysis model, such as the Projection to Latent Structures Discriminant Analysis (PLS-DA) model (Figure 1) can be employed. PLS-DA models the quantitative relationships between the variables X (predictors) and Y (responses) for all the sample groups and can be used to elucidate group differences. However, in these types of plots, each sample is presented by a single point, which does not allow individual markers contributing to the differences between the groups to be observed.
In Figure 1a, the data obtained by ESI- is presented. It can clearly be seen that there are differences between each of the samples. In this plot a general trend can be observed that the authentic product samples fall in the lower quadrant, biased toward the left side, while the counterfeit samples appear at the top and toward the right.