Multi-analyte screening methodologies are essential for monitoring food and environmental samples across the globe. The goal of these methods is to eliminate the compliant samples and to identify the non-compliant samples for subsequent confirmation and quantification. Sensitivity must be in line with the relevant regulatory limits for residues in complex matrices. Also, a method must be validated in accordance with legislative requirements. This method would ideally be rapid, cost effective and a streamlined process, from sample preparation to reporting results.
To date, LC-MS/MS or GC-MS/MS tandem quadrupole technologies meet the requirements above and currently exist as the de-facto technique used to perform these analyses. However, with a constantly increasing number of analytes being added to monitoring and watch lists, the scope of a typical screening method is being extended. In addition, requests to screen for compounds beyond a target list are becoming increasingly common. As a result, many laboratories are progressing towards high-resolution mass spectrometry (HRMS) screening techniques that, in theory, can monitor for an unlimited number of targets at the same time as providing information to help discover unknown compounds or metabolites of interest.
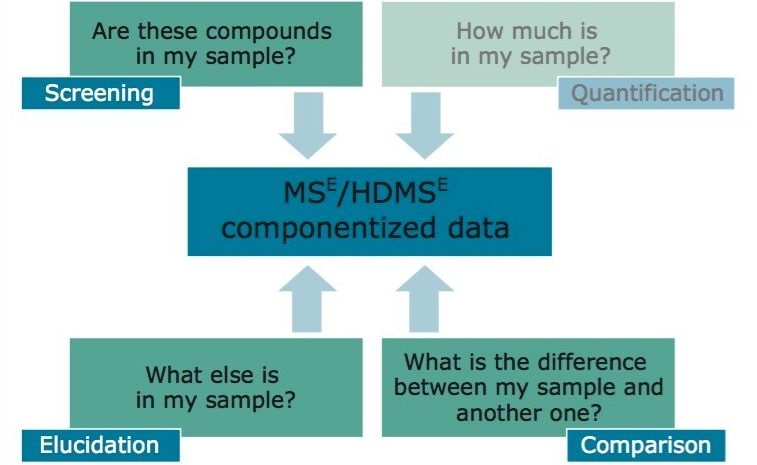
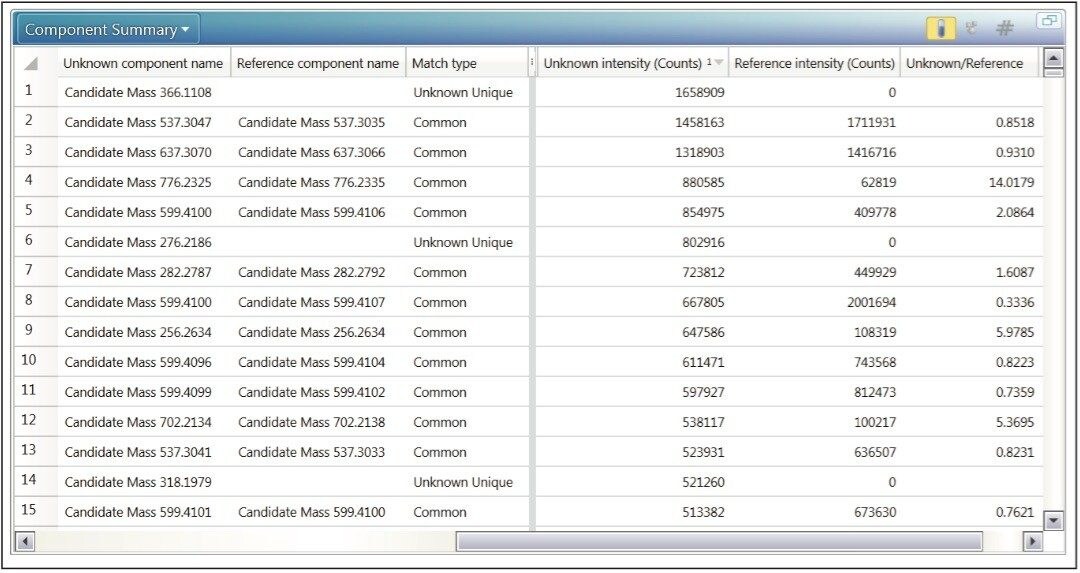
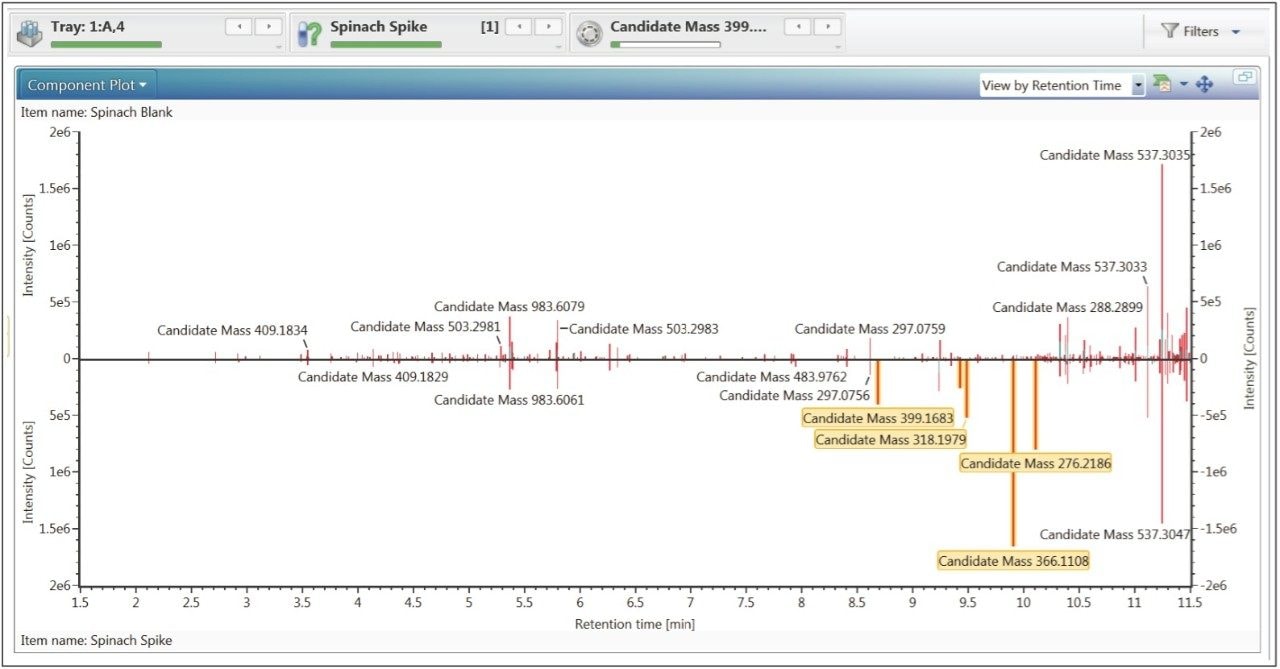
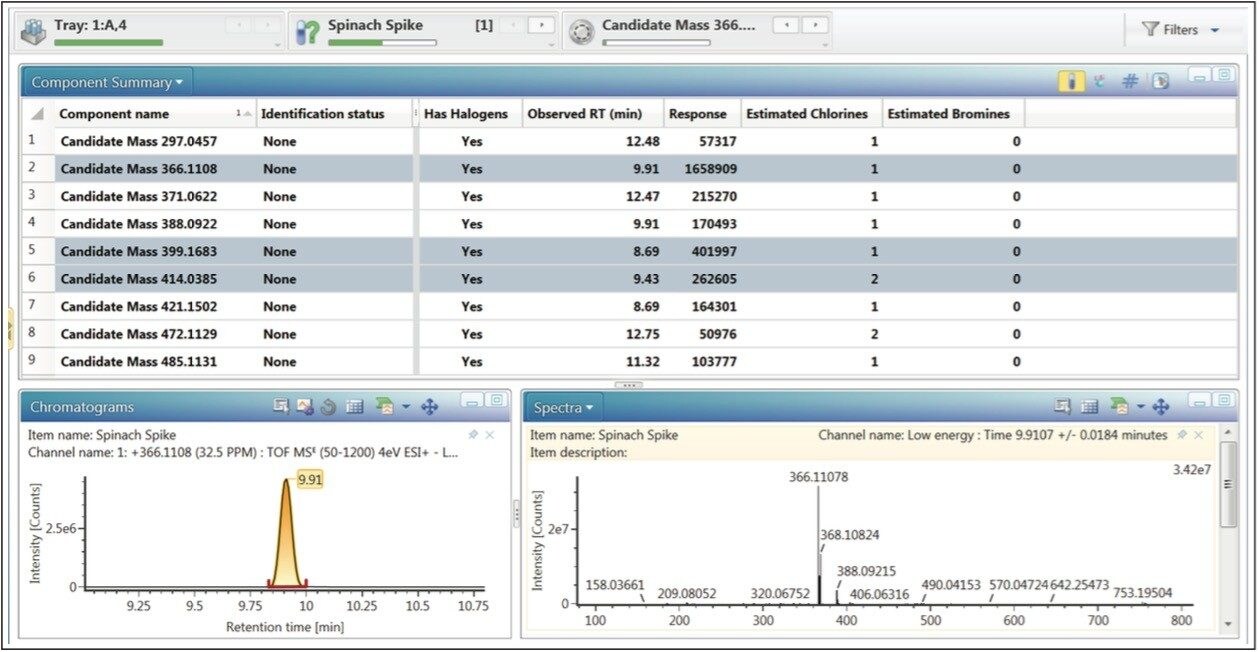
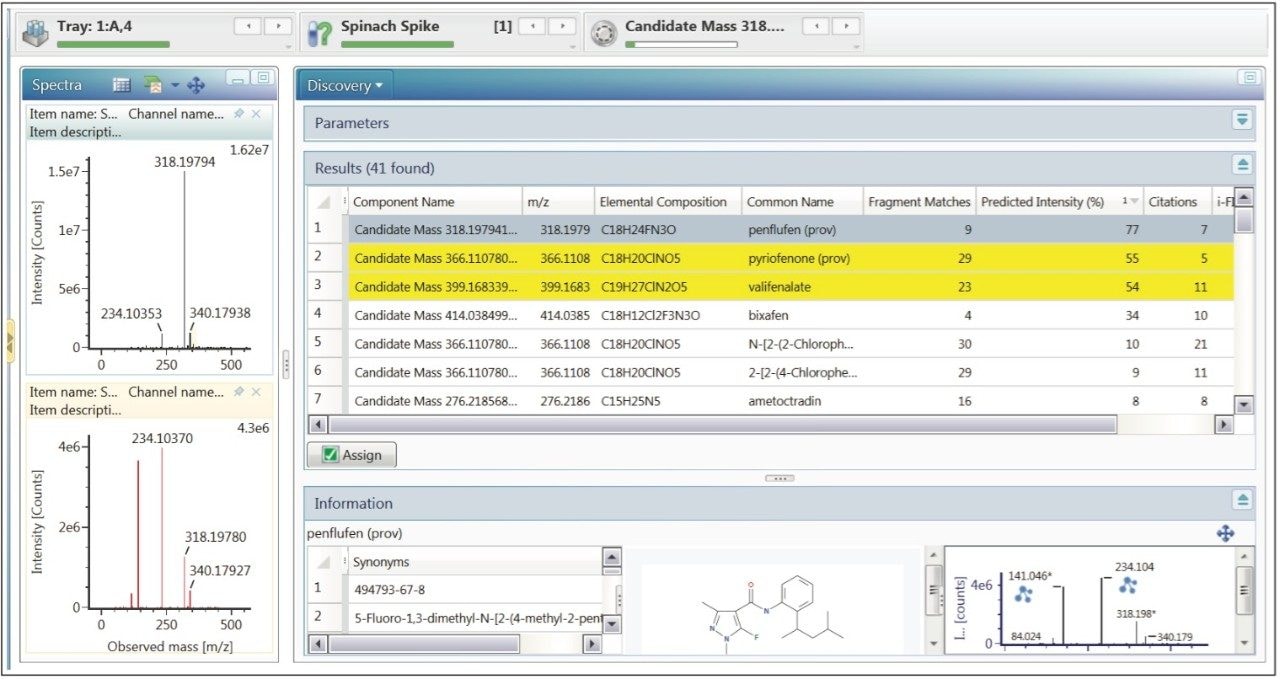
The ease of use and efficacy of a non-targeted, data independent, analysis type (MSE and HDMSE),1 coupled with a state-of-the-art scientific information system (UNIFI) for multi-analyte screening in food and environmental samples is demonstrated with this case study involving an authentic sample analysis. This application note will focus on introducing a novel way users can customize data review within the scientific information system in a routine environment. Details will include how to establish a concise, rapid, facile, and consistent approach to reviewing HRMS data to potentially answer the four questions listed in Figure 1 with a single processing step.